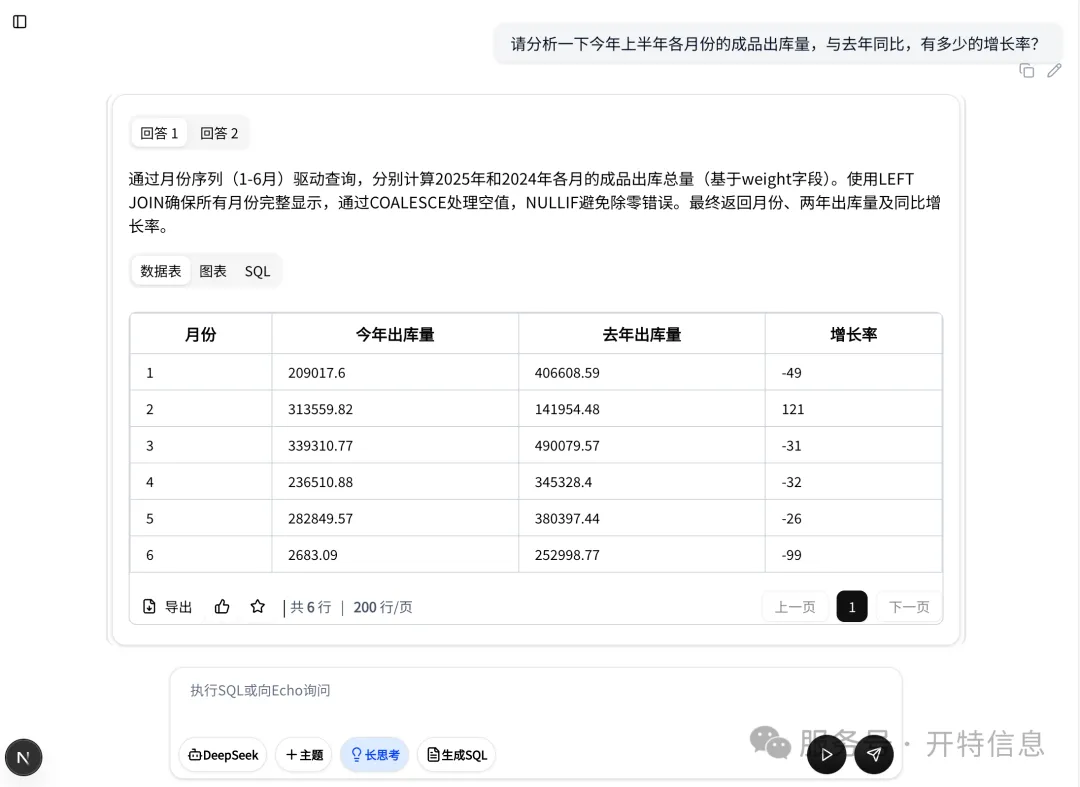
非技術者の方がデータを簡単にクエリできるようにする方法が、すべての組織にとって最も差し迫った課題となっています
従来のデータ検索方法はIT部門や技術スタッフに大きく依存しており、応答時間が遅く効率が低いという課題があります。今日、Te Informationが新たにリリースした
Echo Natural Language Data Query System
は、会話型インタラクションを通じて人間とデータの関係を再定義しています。
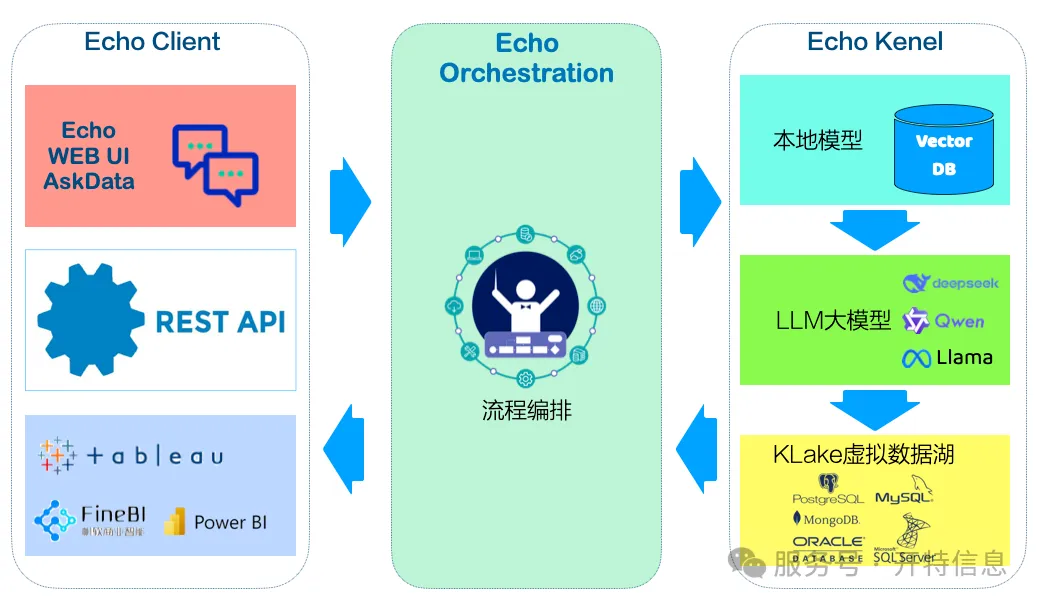
Echoはエンタープライズレベルの自然言語データ検索プラットフォームです。強力な意味理解とローカル知識推論能力を活用し、ユーザーは複雑なクロスデータベース・クロステーブルのデータ検索を完了し、SQL文を自動生成したり結果を直接返したりすることができます——
日常言語で「質問する」だけで
SQLを学ぶ必要はなく、非技術系のスタッフも簡単に始められ、「チャットのようにデータを検索」し、真に「誰もがデータアナリストになれる」というビジョンを実現します。
従来のモデルでは、データ検索は以下の課題に直面することが多いです:
-
プログラミングスキルがないと検索を開始できない
:多くのビジネスユーザーはSQLを理解しておらず、データベース構造についてはなおさらです。
-
ITリソースの制約、応答の遅さ
:エンジニアは多数のアドホックなデータ要求に対応するのに忙殺され、「需要の海」に溺れています。
-
データが散在し、統合が困難
:複数システムにまたがるデータサイロにより、ビジネス課題のクロスデータベース分析はほぼ不可能です。
-
トレーニングのハードルが高く、導入が遅い
:多くのText2SQLソリューションは大量のトレーニングデータを必要とし、導入サイクルが長くコストが高くなります。
Echoはこれらの問題を完全に解決するために作成されました!
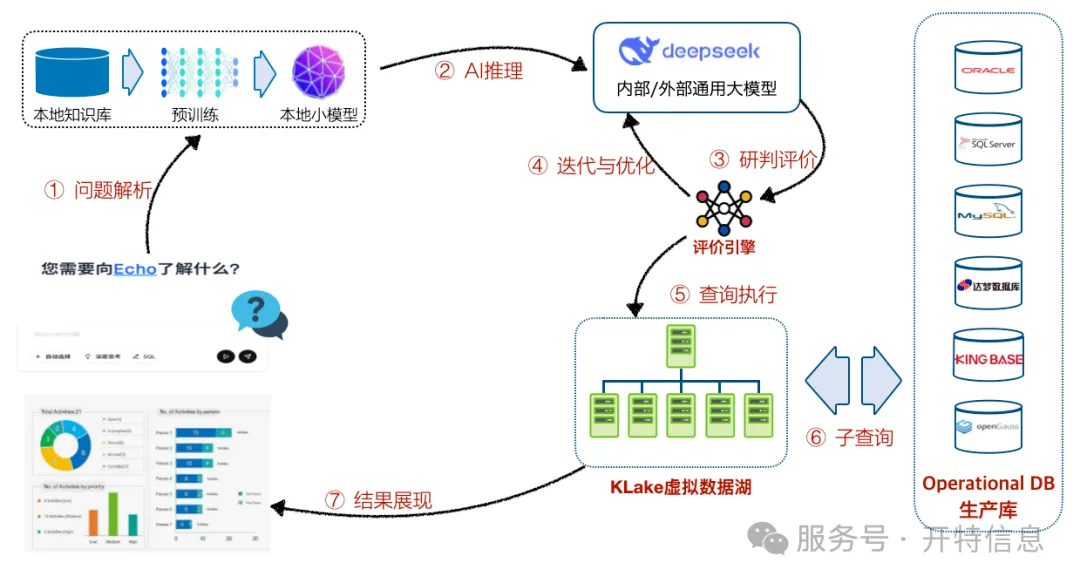
Echoは自然言語を「理解」するだけでなく、堅牢なデータ適応能力と効率的な検索性能を備えています:
-
広範なデータソースサポート
:ORACLE、SQL Server、MySQL、DB2、Dameng、Kingbase、openGaussなどの主流データベース、およびExcelやCSVなどのファイル形式に対応しており、マルチソース異種データに適応します。
-
クロスデータベースクエリ機能
:単一のユーザー質問で複数のデータベースを同時にクエリでき、真の「クロスシステム協調分析」を実現します。
-
直接結果表示またはSQL生成
:ビジネスユーザーが直接使用できる可視化結果を出力するか、技術スタッフがさらに改良するためのSQLステートメントを生成できます。
-
高性能MPPエンジン
:Massively Parallel Processing(MPP)アーキテクチャを基盤としており、クエリがソースデータベースのパフォーマンスに与える影響は最小限です。
-
トレーニング不要ですぐに使用可能
:導入に大量の過去のQ&Aデータは必要ありません。強力な適応性を備え、さまざまなビジネスシナリオに柔軟に導入できます。
-
ファジー意味認識とマルチパス予測
:質問の説明が不明確な場合でも、システムは意味分析に基づいて複数の代替回答を提供し、ユーザーが意図を徐々に明確にするのを支援します。
Echoの応用は、データ効率を大幅に向上させるだけでなく、企業内でのデータ利用方法を根本的に変革します:
-
ITリソースを解放してガバナンスに集中
:ITチームはデータ要求を受動的に処理するのに縛られなくなり、代わりにデータガバナンスと標準化に集中できます。
-
ビジネスユーザーを強化して応答時間を短縮
:ビジネススタッフは待たずに主要データに自力でアクセスでき、意思決定を加速します。
-
データ利用率を向上
:「他人にクエリを待つ」から「積極的に質問する」への転換により、データから価値への変換が強化されます。
-
セキュリティ監査と権限制御の強化
: すべてのクエリ活動の監査をサポートし、権限システムと統合して、最小権限の原則の遵守を確保します。
将来的には、データクエリは技術者の専有スキルではなく、すべてのビジネス参加者の基本スキルとなります。Echoは技術的障壁を打破し、「データエクイティ」を真に実装するために開発されました。