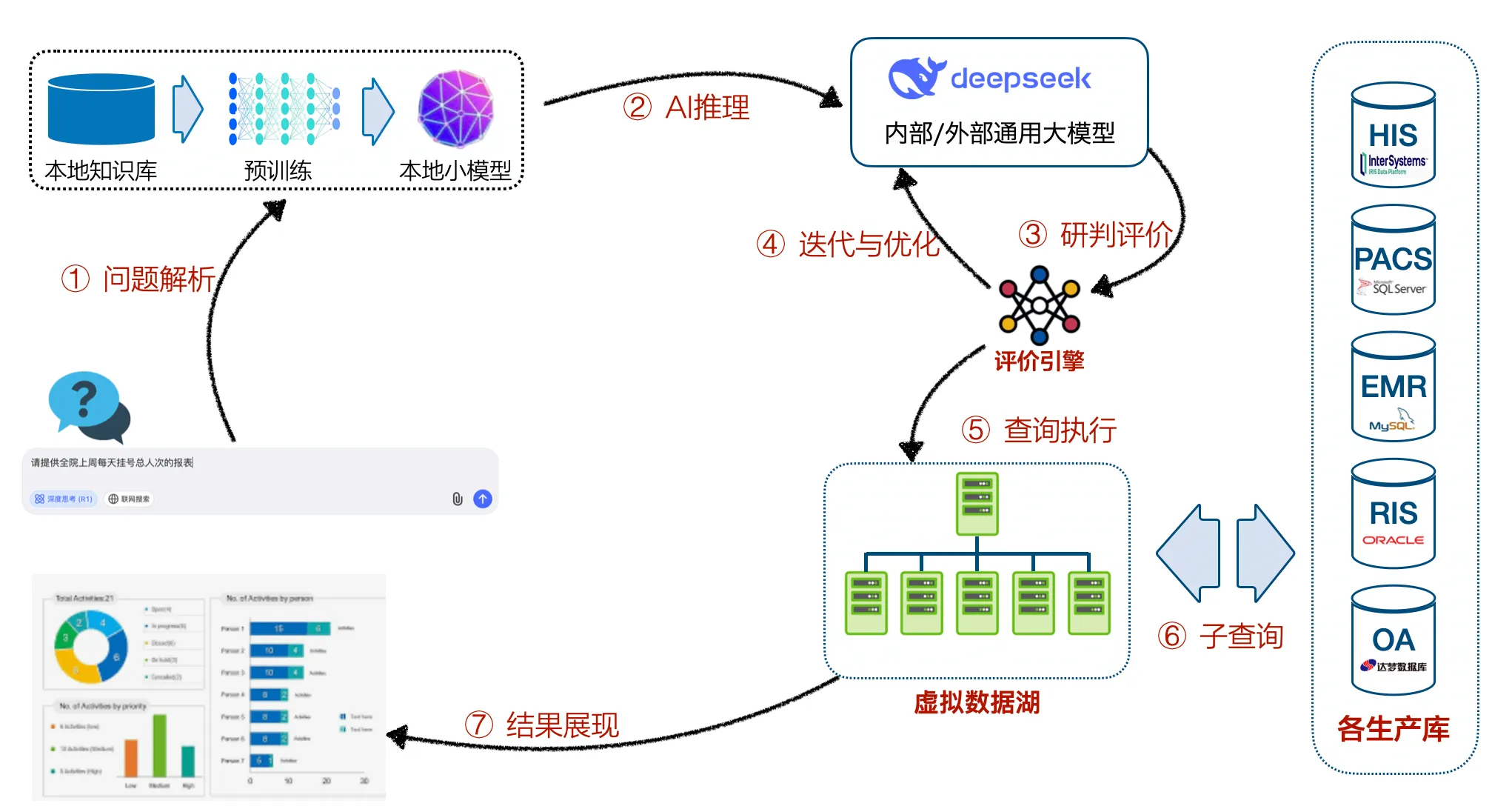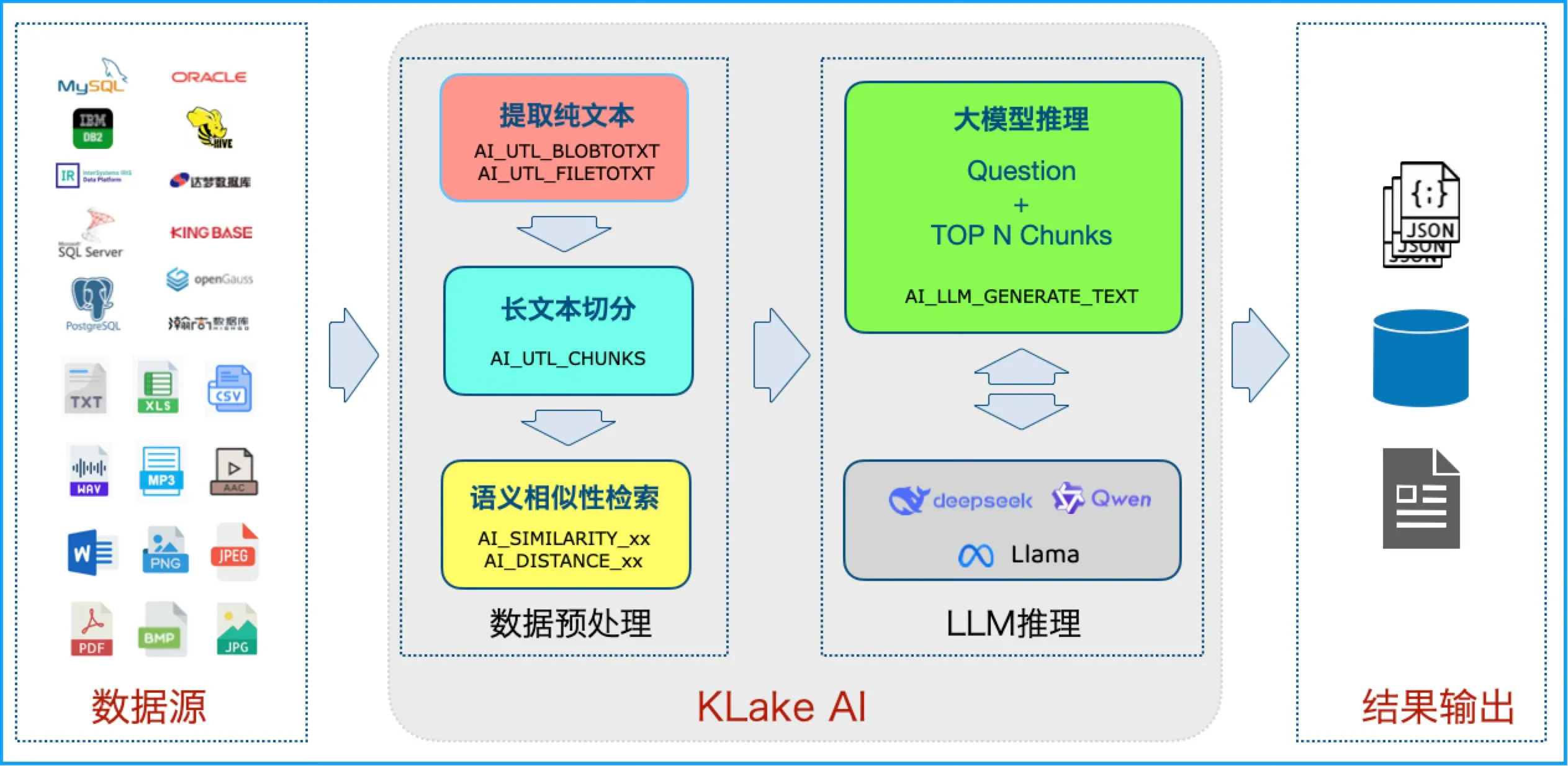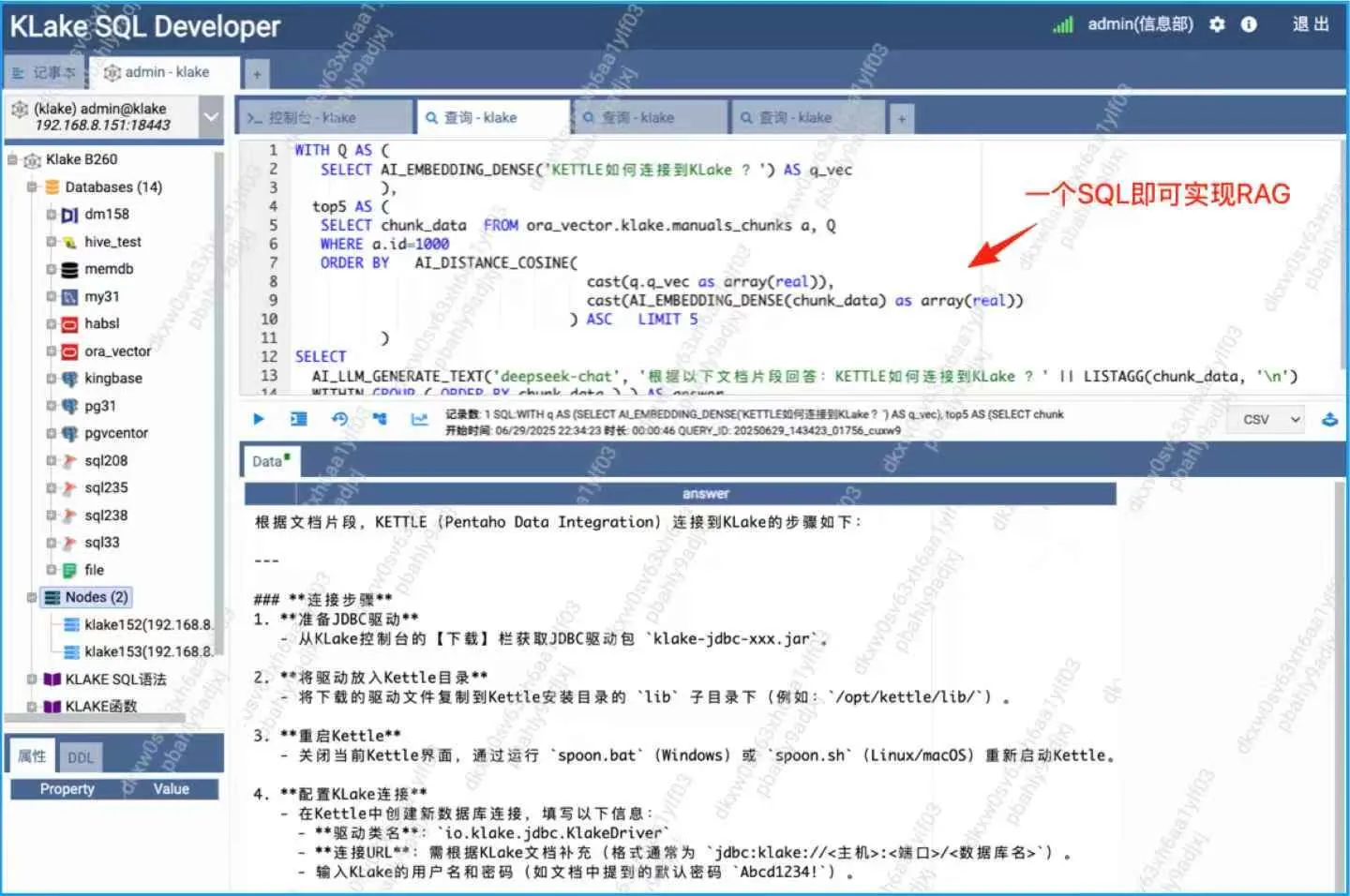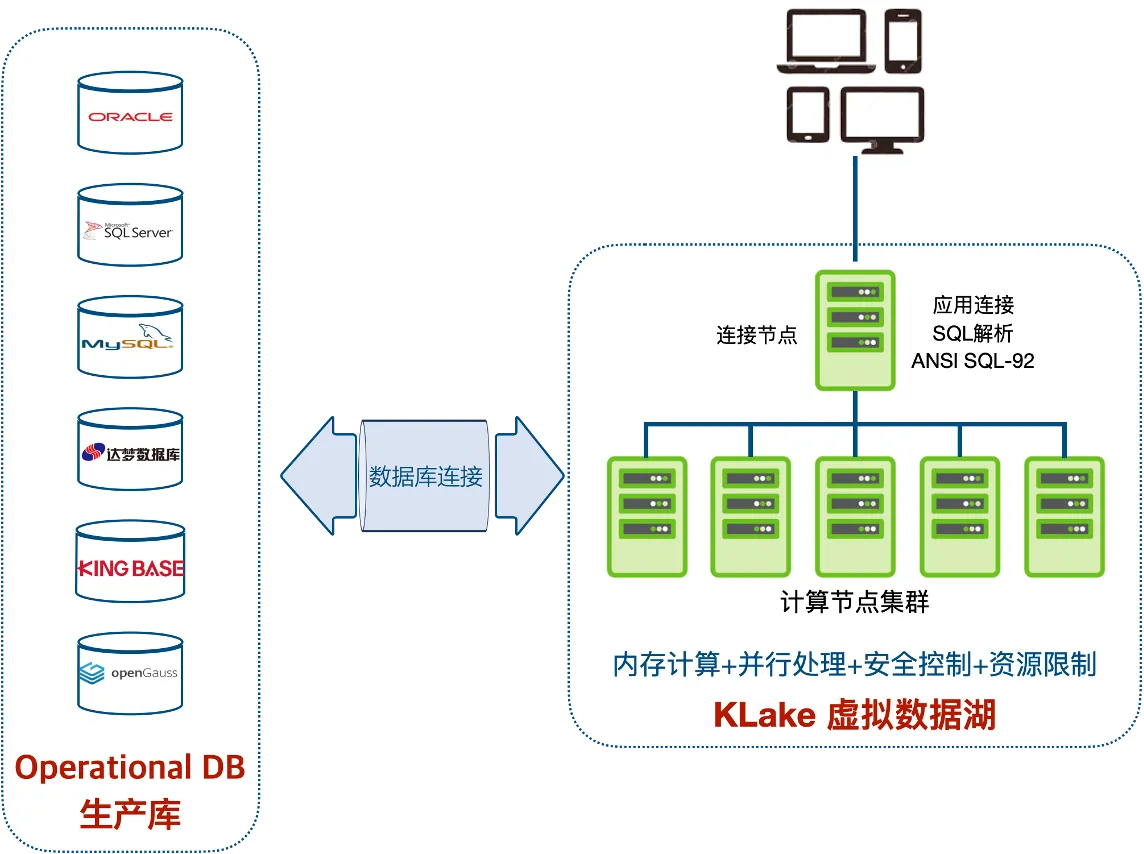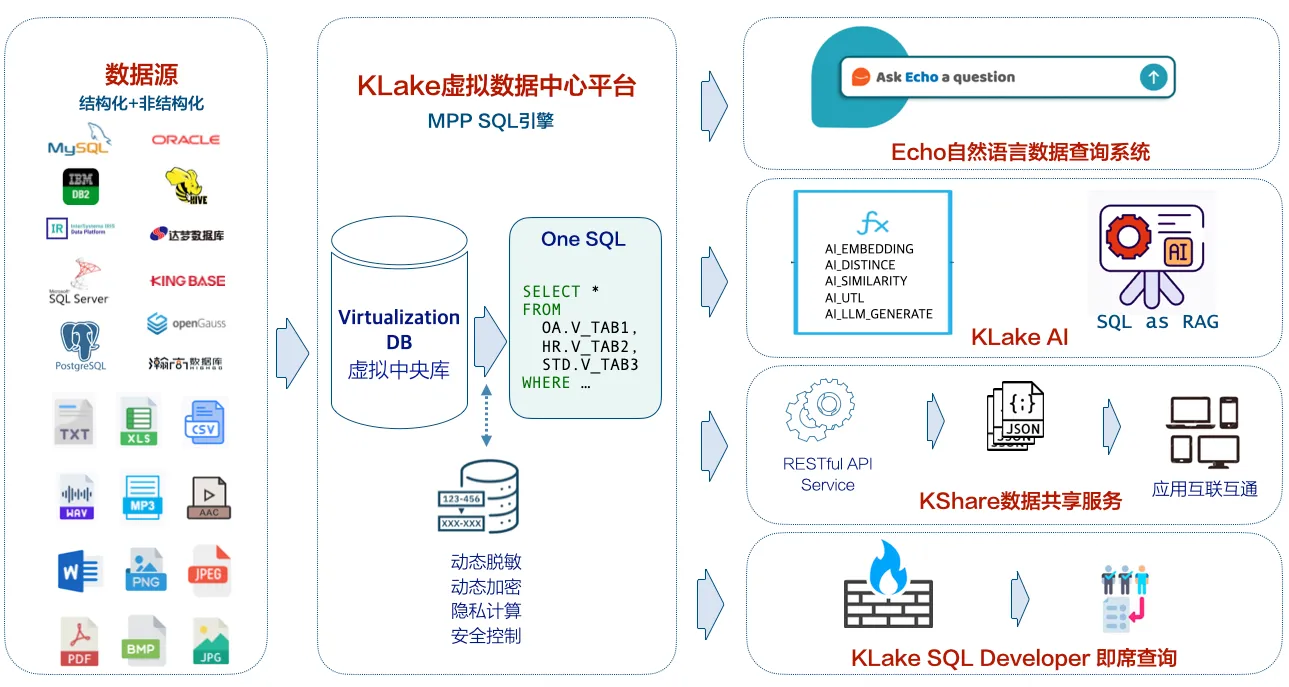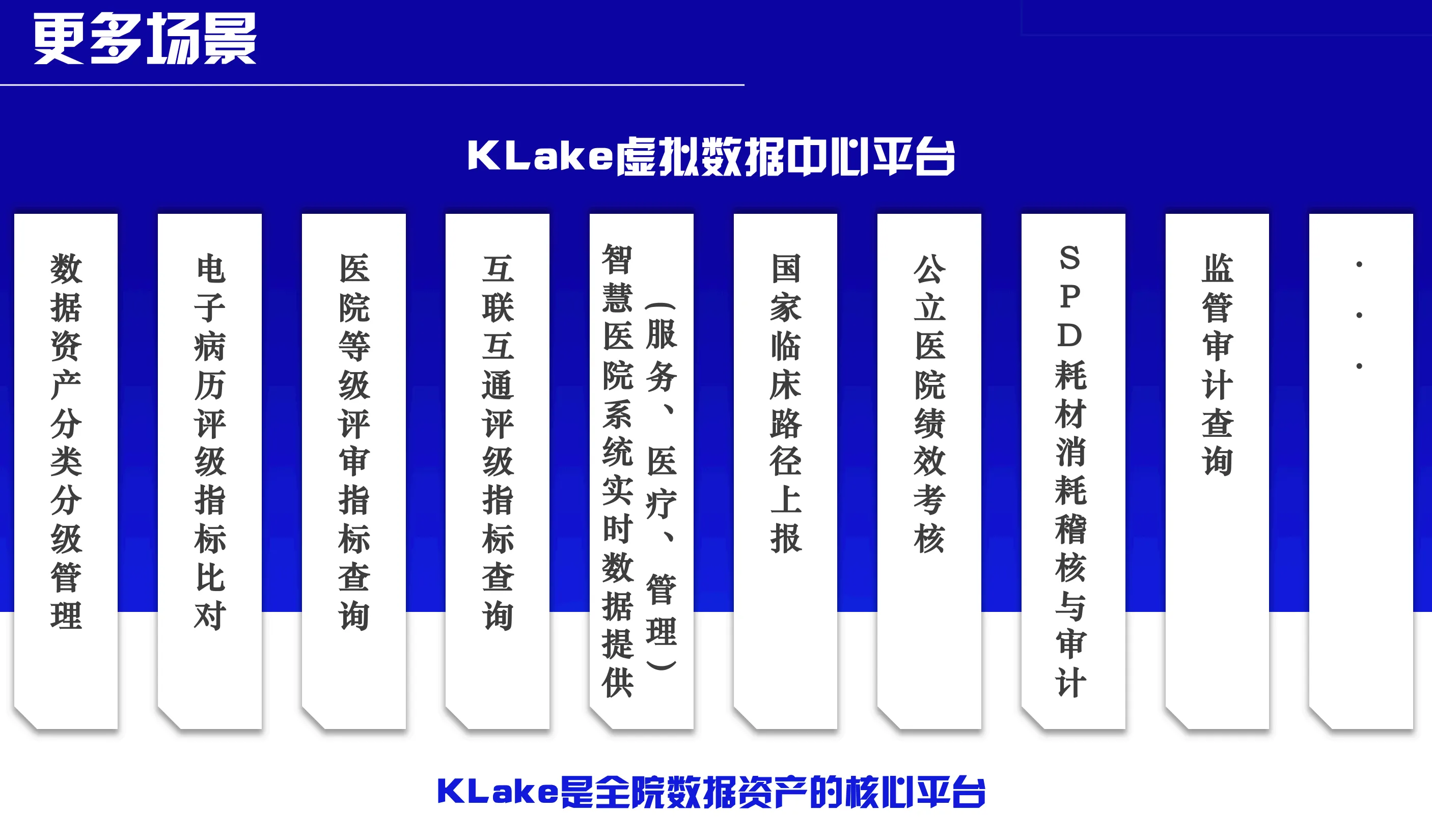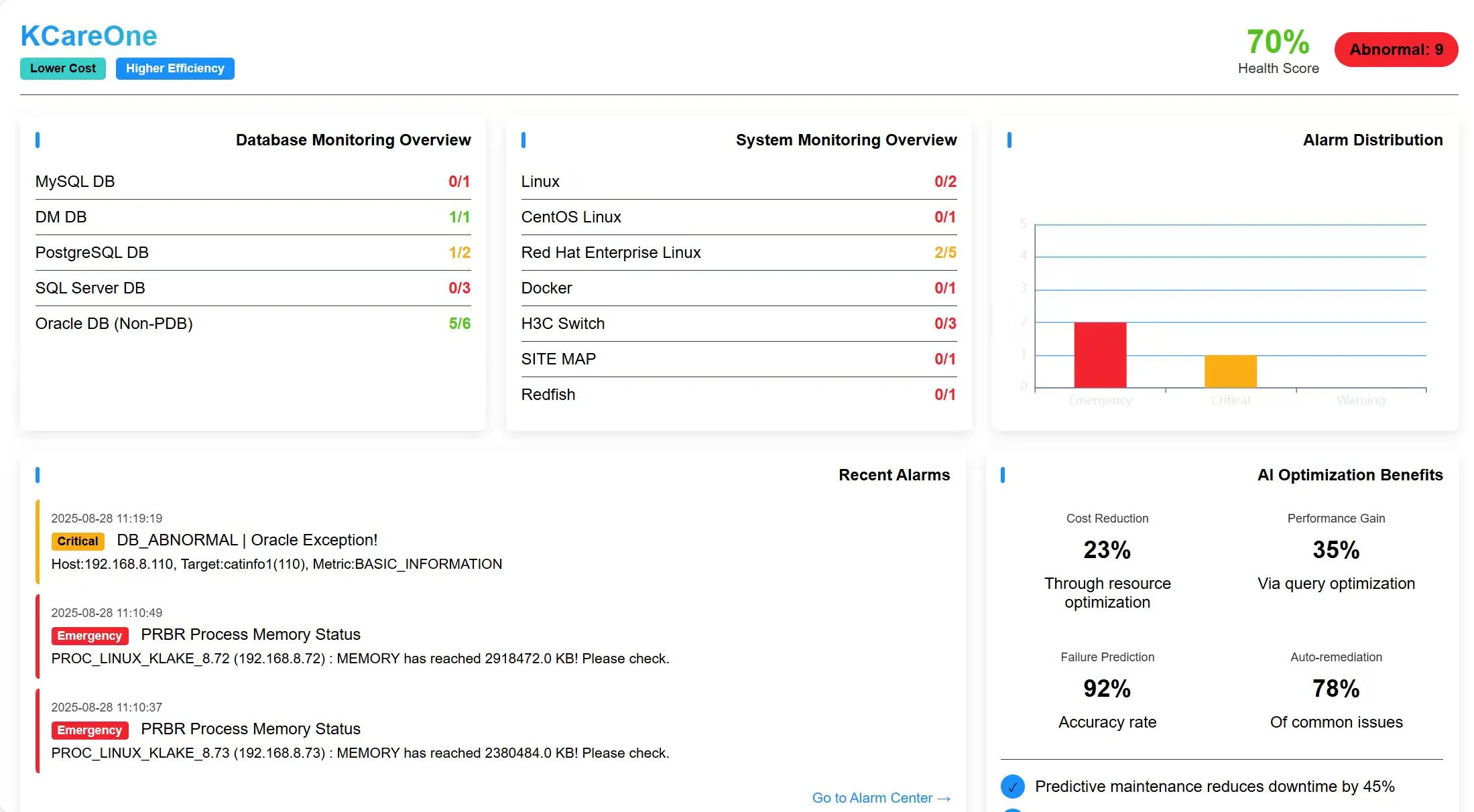

-
①
非リアルタイムデータ
ETL経由で転送されるデータは、本番システムのデータよりも遅れており、不整合や品質問題のため再処理が必要になることが多い。 -
②
高い導入コスト
スキーマオンライトを使用して数百のデータベースからデータを一元化するには、膨大な時間、労力、資金が必要であり、リアルタイム同期を実現することはできない。 -
③
パフォーマンスのボトルネック
一般的に、各ビジネスデータベースは、データレポート作成、統合プラットフォームの同期などのタスクを担当する必要がある。ETLプロセスはソースデータベースに負荷をかけ、運用パフォーマンスを低下させる。
.webp)